主線
KAI K8s之路 04|Probe 是什麼?Running 不等於 Ready
Service 給了穩定入口,但 Kubernetes 還要判斷 Pod 能不能接流量。這篇用 readiness、liveness、startup probe 拆開「活著」「能服務」「慢啟動」三件事,避免把服務打進 restart loop。
Running 只是程式起來;Ready 才能接流量。Probe 是 workload 對 Kubernetes 回報狀態的訊號。
先把 probe 責任拆清:readiness 控流量、liveness 控重啟、startup 保護慢啟動,再查 Event 和 EndpointSlice。
上一篇我們把 Service 想清楚了:
Pod 會換,入口不能飄。
但入口穩定,不代表後面每個 Pod 都真的能服務。
這就是很多新手第一個卡點:
Service 看起來正常,DNS 也正常,為什麼 request 還是 timeout、502,或者偶發失敗?
我會先記這句:
Running 只是程式起來;Ready 才是可以接流量。Probe 是 Kubernetes 判斷 workload 狀態的訊號。
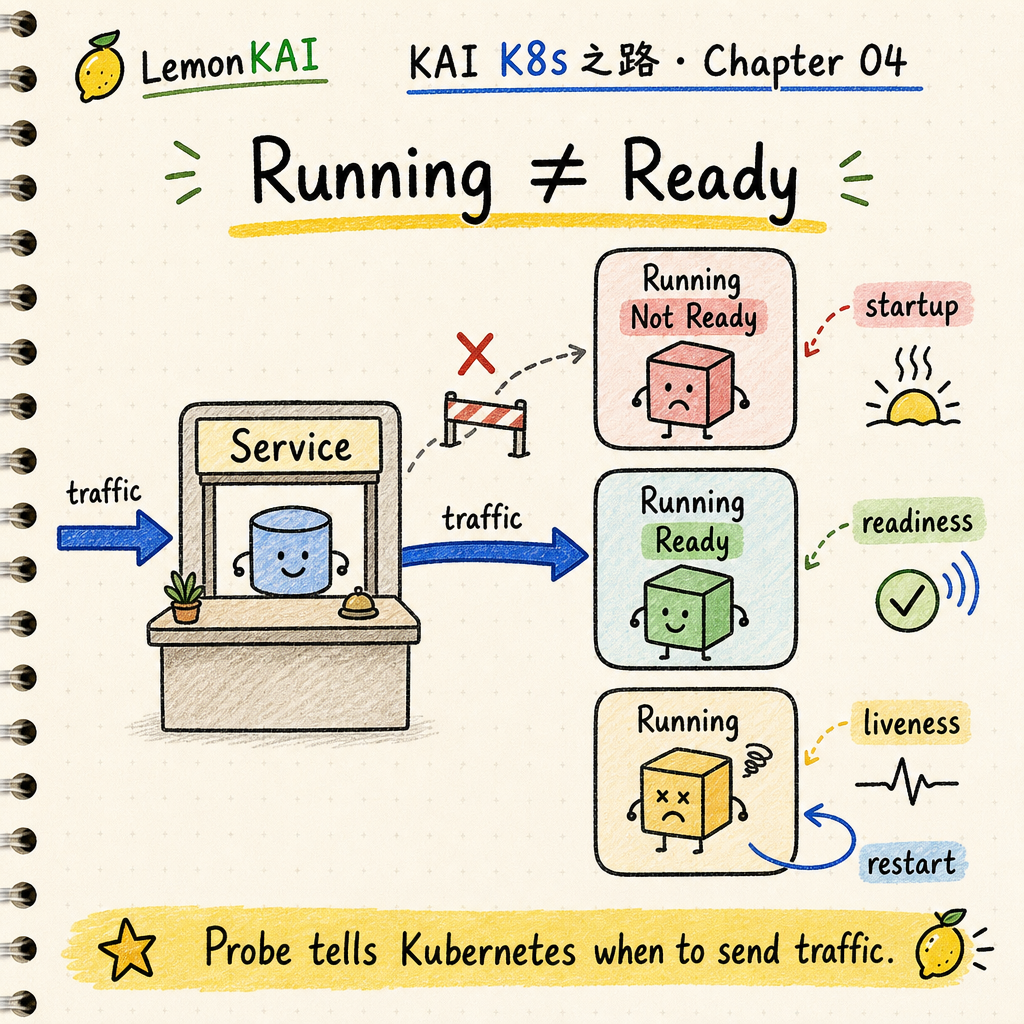
先不要把 Running 當成 Ready
Pod 進到 Running,只代表 container process 已經被拉起來。
但你的應用可能還在做這些事:
- 連資料庫
- 載入設定
- warm cache
- 等依賴服務可用
所以 Running 不等於「現在可以穩定回應請求」。
如果這時候就讓 Service 把流量導進來,用戶看到的通常不是「快」,而是「時好時壞」。
用餐廳營業想 Probe
我會用餐廳例子記這章。
店裡燈亮了,不代表可以接客。
廚房可能還在備料,POS 還沒連上,員工還在開晨會。
這時候門口掛「營業中」,客人進來點不到東西,體驗反而更差。
Probe 就是在替 Kubernetes 回答三件事:
startupProbe:我是不是還在正常開機,先不要太早判我死readinessProbe:我現在能不能接單,不能就不要把流量導進來livenessProbe:我是不是卡死到該重啟
Probe 三種角色,不要混
我會把它們分工記成一句話:
readiness 控流量,liveness 控重啟,startup 保護慢啟動。
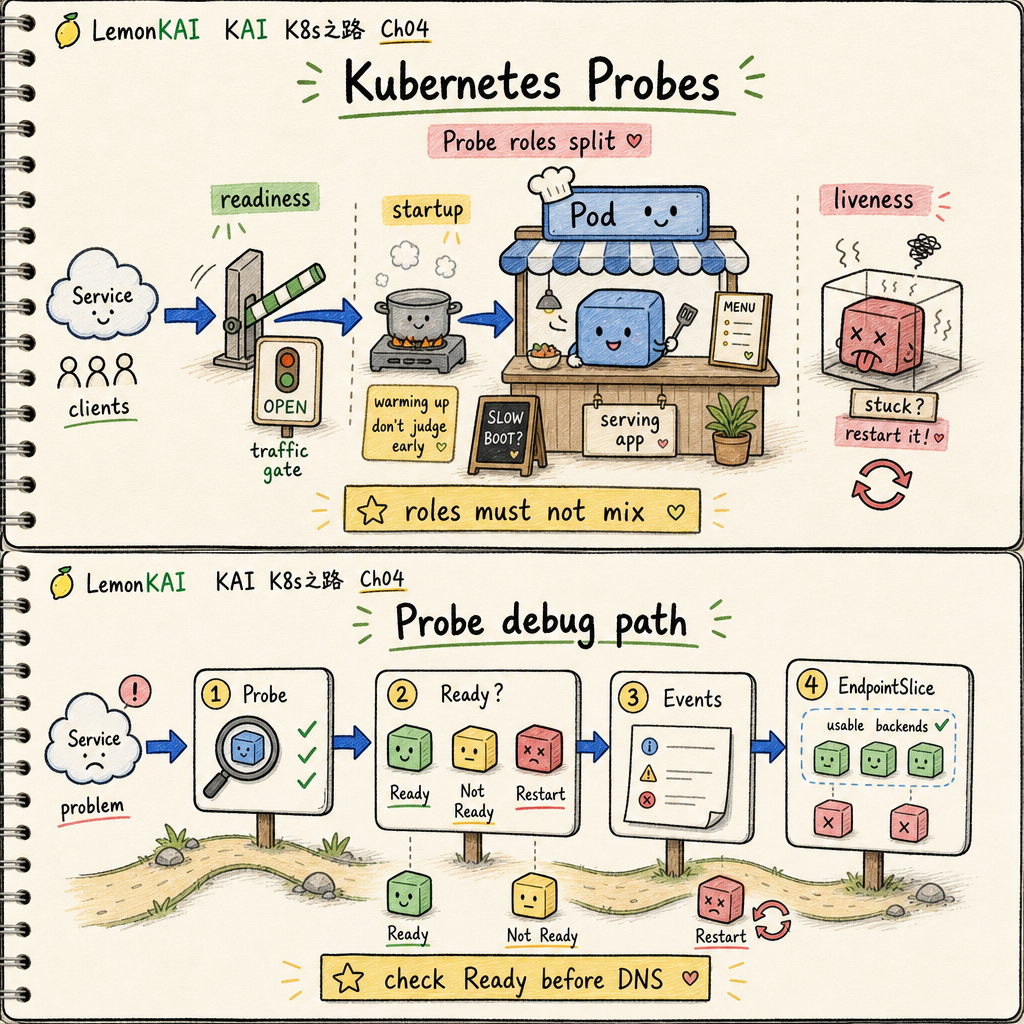
這三個 probe 可以檢查同一個 endpoint,也可以分開。
重點不是 endpoint 一不一樣,而是語義不要打架。
如果把 readiness 和 liveness 混著用,系統就會把「暫時慢」誤判成「應該重啟」,最後把小抖動放大成事故。
Kubernetes 實際在做什麼
這裡給一個技術上夠準、但不繞的版本。
kubelet會週期性執行 probe(例如 HTTP、TCP、exec、gRPC)。readinessProbe失敗時,Pod 會被標成 not ready;對應 Service 的 EndpointSlice 會把這個 Pod 從可用端點名單拿掉。livenessProbe連續失敗超過failureThreshold,kubelet 會重啟該 container。startupProbe若有配置,在它成功前,liveness 和 readiness 不會開始執行。
這些行為是 Kubernetes 官方文件明確定義的,不是社群慣例。
參考:https://kubernetes.io/docs/concepts/workloads/pods/probes/
一個簡化設定範例
apiVersion: v1
kind: Pod
metadata:
name: web
spec:
containers:
- name: web
image: ghcr.io/example/web:1.0.0
ports:
- containerPort: 8080
startupProbe:
httpGet:
path: /healthz
port: 8080
periodSeconds: 10
failureThreshold: 30
readinessProbe:
httpGet:
path: /ready
port: 8080
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
livenessProbe:
httpGet:
path: /healthz
port: 8080
periodSeconds: 10
timeoutSeconds: 2
failureThreshold: 3這份配置的重點不是參數值,而是責任切分:
startupProbe給慢啟動保護時間readinessProbe控制是否進 Service 流量池livenessProbe只處理真的卡死情境
新手最常踩的坑
1) 把 Running 當成可以接流量
這是最常見誤判。
Service 有 endpoint,不代表 endpoint 現在能穩定服務。
2) 用 liveness 解決 readiness 問題
依賴服務短暫抖動時,如果直接讓 liveness 判死,服務會被重啟到更不穩。
3) readiness 設太重
Probe endpoint 如果自己就很重,可能把健康檢查變成壓力來源。
4) 慢啟動服務沒有 startupProbe
沒有 startupProbe 時,很容易在啟動期就被 liveness 提前殺掉。
我會怎麼 inspect
如果有人說「Service 不通」,我會先查 Probe,不先怪網路。
kubectl get pod -n <ns>
kubectl describe pod <pod-name> -n <ns>
kubectl logs <pod-name> -n <ns> --previous
kubectl get endpointslice -n <ns> -l kubernetes.io/service-name=<svc-name>我會重點看:
READY欄位是否長期 0/1RESTARTS是否持續增加- Events 裡是 readiness fail 還是 liveness fail
- EndpointSlice 是否仍有 ready backend
- probe path / port / timeout / threshold 是否過於激進
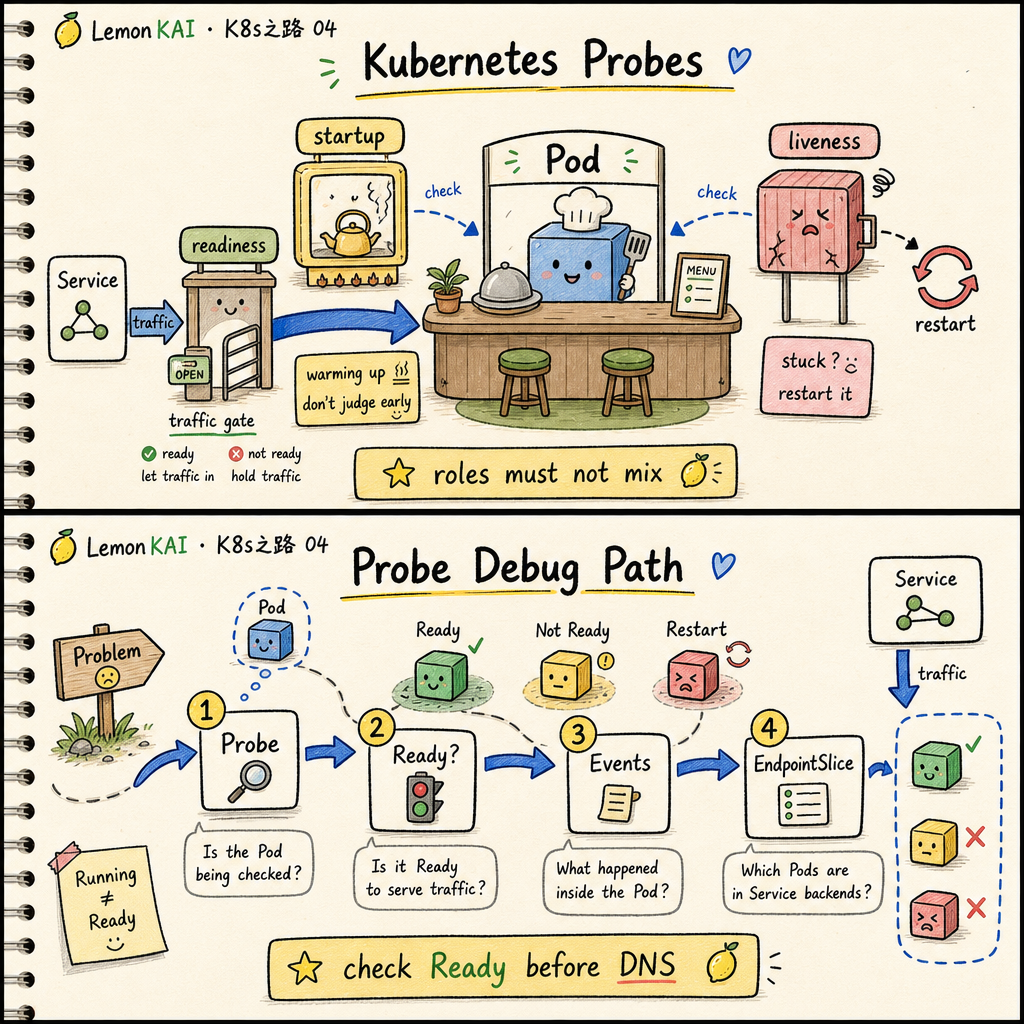
一句話版本:
Service 不通時,先問 Pod 有沒有 Ready,再問網路。
我對 Probe 的記法
我不會把 probe 記成「健康檢查功能」這麼空。
我會把它記成一份協議:
workload 用 probe 告訴 Kubernetes:什麼時候我能接流量,什麼時候我只是慢,什麼時候我真的該被重啟。
協議寫對,平台會穩定幫你收斂。
協議寫錯,平台也會很穩定地幫你製造事故。
這篇先記住三件事
Running不等於Ready;Ready才是可接流量readiness控流量、liveness控重啟、startup保護慢啟動- 查 Service 問題時,順著
Probe -> Ready 狀態 -> EndpointSlice走,通常比先查 DNS 有用
下一篇會接著看:ConfigMap / Secret 是什麼?為什麼配置和鑰匙不應該寫死在 container 裡。